
Our latest article explains the difference between various kinds of deepfakes and how to detect images generated by commercial text-to-image models (Dall-E, Midjourney) with Amped Authenticate’s newest Diffusion Model Deepfake filter.

Dear friends, welcome back to the Amped blog! Just a few days ago, we released a great update to Amped Authenticate, featuring lots of new tools and features. Today, we’ll dive deeper into one of the hottest additions: the Diffusion Model Deepfake filter! Keep reading to start the journey!
The Deepfakes Era
There’s really no need to stress the impact that deepfakes are bringing to our society. It started with some funny face-swapping, where most of the image was not manipulated. Now, we’re witnessing pictures entirely synthesized by the machine in a few seconds, from a simple text description. It is impressive. And scary.
While nowadays there is a tendency to call “deepfake” each and every manipulated image, the truth is that there are several different kinds of deepfakes based on completely different AI techniques. So, when it comes to detecting deepfakes, you first need to ask yourself what you are looking for and then select the proper tools to verify the images.
Thus, let’s briefly introduce three different classes of deepfakes and the process behind their generation. We’ll then focus on the latest additions to Amped Authenticate, the Diffusion Model Deepfake filter.
Face-swaps, GAN Deepfakes, Text-to-image Deepfakes
Face-swaps
By now, everyone has seen at least one video in which Tom Cruise’s or Nicholas Cage’s face was re-enacted or swapped. If you didn’t, here is a funny one where Nicholas Cage’s face replaces Amy Adams’ while she sings I Will Survive.
This is among the first kind of deepfakes we’ve witnessed. Although there’s a fairly complex processing pipeline behind creating a good quality deepfake of this kind, AI prominently enters the game when it comes to “converting” Amy’s face to Nicholas’s. This is done via an auto-encoder, a specific neural network architecture. In a nutshell, you first create a network that is very good at compressing and decompressing Nicholas’ facial images and another for Amy’s. Then, you take Nicholas’ face and generate its latent (“compressed”) representation. The next step is using Amy’s decompression branch instead of Nicholas’. You’ll then need to put the converted face back in the frame, warp it, etc., so it still takes quite some work.
Currently, Amped Authenticate does not feature a dedicated filter for video deepfake detection, but our research team is working hard on it!
GAN-Synthesized Faces
Another famous source of deepfakes is thispersondoesnotexist.com. When you visit the page, you’re presented with a face like this.

Now, as the website name suggests… this person does not exist. The face is created (“hallucinated” is the technical term) by a neural network. How do you create a neural network capable of doing this? In this specific application, they use a Generative Adversarial Network (GAN). It’s an architecture with two neural networks, a Generator and a Discriminator. The Discriminator is trained on millions of real face images, and its goal is to distinguish real faces from generated faces. The Generator starts from random noise and generates an image, which is sent to the Discriminator for auditing. The trick is that the output of the Discriminator is used to improve the Generator’s ability to fool “him”. After some millions of iterations, the Generator will become good enough to fool the Discriminator. You can now trash the Discriminator and use the Generator to create visually compelling faces.

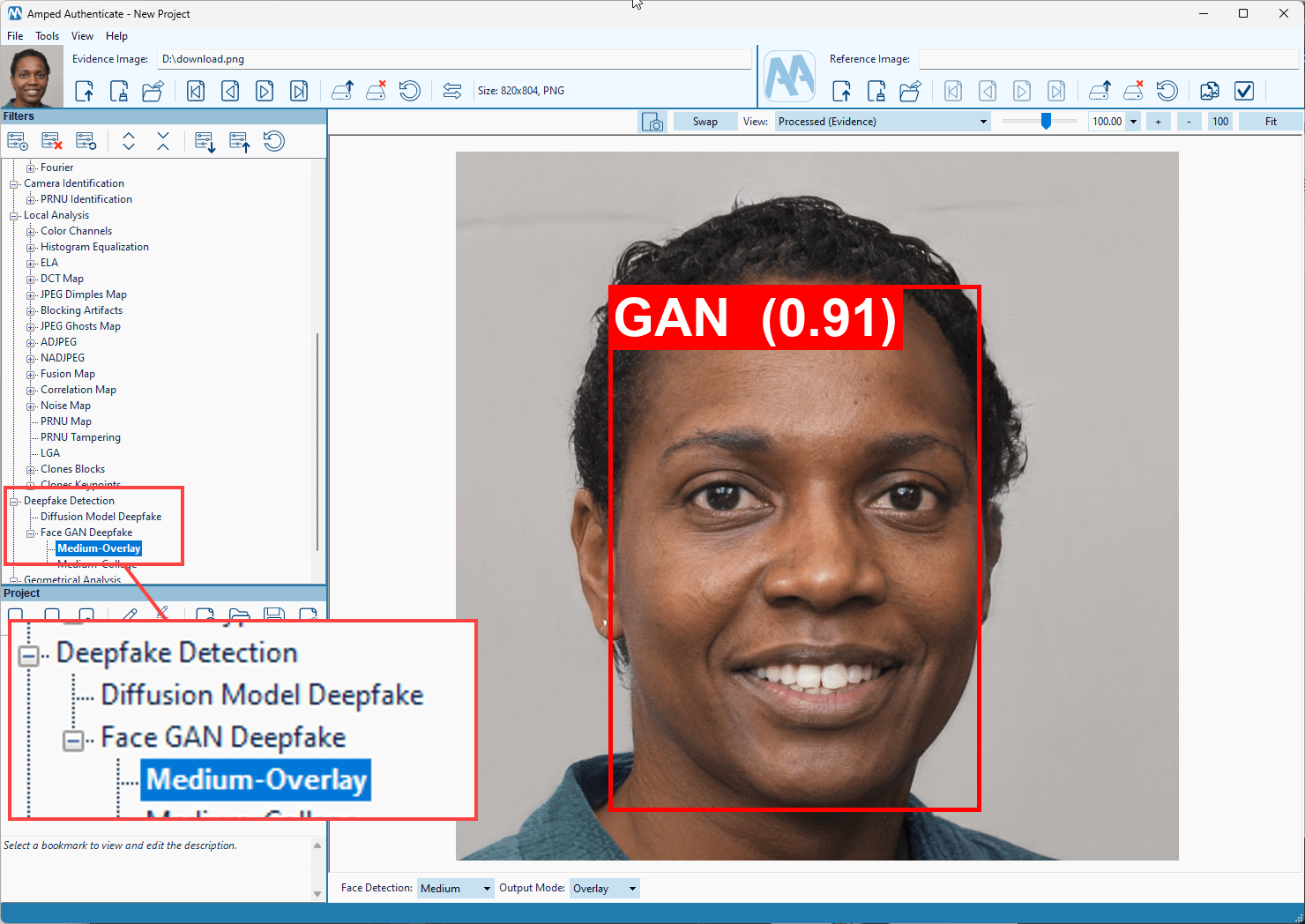
Amped Authenticate has a dedicated filter to detect this kind of faces. It is called Face GAN Deepfake, and it is found under the Deepfake Detection category. You can read how it works in this article on our blog.
Text-to-image Synthesized Images
Let’s now move to the most recent and trendy deepfakes category: diffusion models. Once again, there’s a completely different deep-learning architecture behind creating these images.
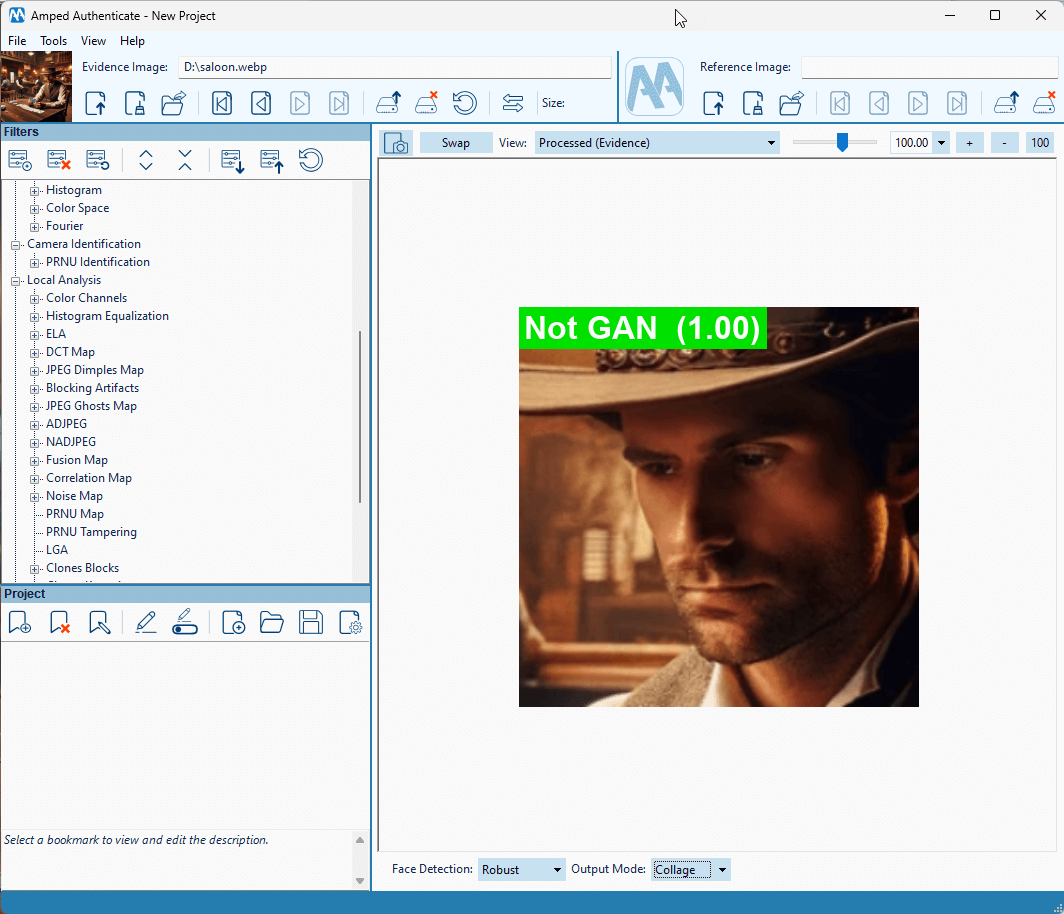
The technique involves using deep neural networks to progressively add noise to an image until there is complete noise (forward diffusion). It also includes a reverse process to recover intermediate versions of the image by removing this noise (reverse diffusion). This is achieved by using a neural network that has been specifically trained for this task. When recovering an image, the noise reduction process can be guided by external data, such as a text prompt. This allows the user to direct the image reconstruction towards a specific concept, like “a man playing cards at a table in a western movie saloon”. Here’s what was produced on Dall-E-3 in about 10 seconds.

Diffusion-based image generators can transform the text into an image by mapping both the image pixels and textual prompts to a shared “semantic latent space”. This enables the model to interpret the visual context of the words from a text prompt and decode it into an image. Additionally, it is possible to combine multiple textual concepts within this latent space and decode them to generate an image that includes all those concepts. For example, combining “man,” “cards,” and “saloon” as mentioned above.
Clearly, a diffusion deepfake is quite different from a GAN-generated image. That’s why if you try sending the above image through Authenticate’s Face GAN Deepfake filter, you’ll be told that the player’s face is not GAN-generated. It’s actually the correct answer!
The Diffusion Model Deepfake filter
Amped engineers have been researching and monitoring for months the state-of-the-art in detecting deepfakes created by diffusion models. We eventually identified a recent work by Cozzolino et al. as very promising. This work showed excellent performance both in the scientific paper and our internal validation.
The filter first extracts some higher-level features known as CLIP (Contrastive Language-Image Pre-training) and then uses an SVM (Support Vector Machine) to classify these features as coming from a diffusion model image or not. This approach significantly increases the method’s robustness to post-processing.
Since Amped Authenticate already features the Face GAN Deepfake filter, we opted for training the new Diffusion Model Deepfake filter only to detect diffusion images generated by two common commercial tools, Midjourney and Dall-E-3, plus images generated by an implementation of Stable Diffusion.
We gathered a diverse set of real images and used roughly 2k images for training and 42k images for testing. Similarly, we used roughly 1.5k deepfake images for training (500 per diffusion model) and 6.2k images for testing. It should be noted that these images are not used to train the neural network that extracts CLIP features. A pre-trained model for that task is already available. The images of our training set are only used to train the SVM classifier.
Results are reported in tabular form. The first row shows the class that obtained the highest output probability from the SVM classifier. The following rows show the probability associated with each output class. Being probability values, they always add to 1 (leaving out rounding of values to the third decimal point).
This is the result for the saloon image above:
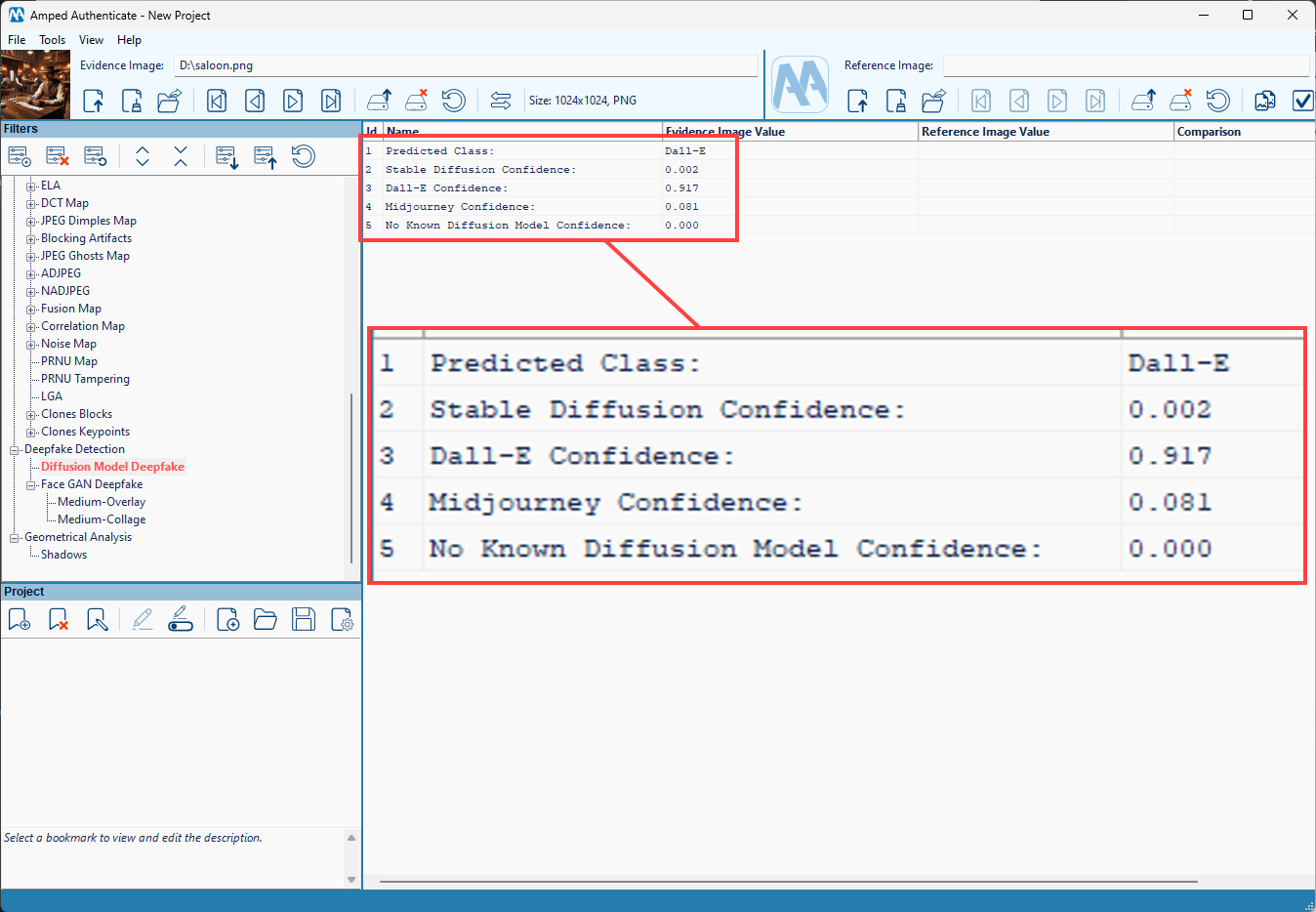
As you can see, the classifier confidently assigns the image to the Dall-E class, and correctly so! Of course, a result where probabilities are evenly distributed among various classes suggests that the classifier is unsure and reduces our confidence in the predicted class.
Results Interpretation and Robustness
It is important to understand that even when a single class is assigned the entire probability, that doesn’t mean you can be 100% sure the output is correct. It only means the classifier is “very confident”, but it can still be wrong, and that’s not “a bug” ;-).
As anticipated, we were positively impressed by the method’s generalization capabilities. Generalization means the ability of an AI-based method to perform well on data that differs from what was seen during the training stage. It doesn’t take a genius to understand that creating a training dataset that closely represents every possible image content and source is an impossible task.
The method behind the Diffusion Model Deepfake filter does not simply rely on “low-level traces” such as those left in the frequency domain or in local pixel correlations. These traces are indeed dependent on the image source and are easily erased even by sharing an image via social media (which often implies rescaling and compression). Instead, the filter is based on the more robust CLIP features, which bring good resilience to post-processing.
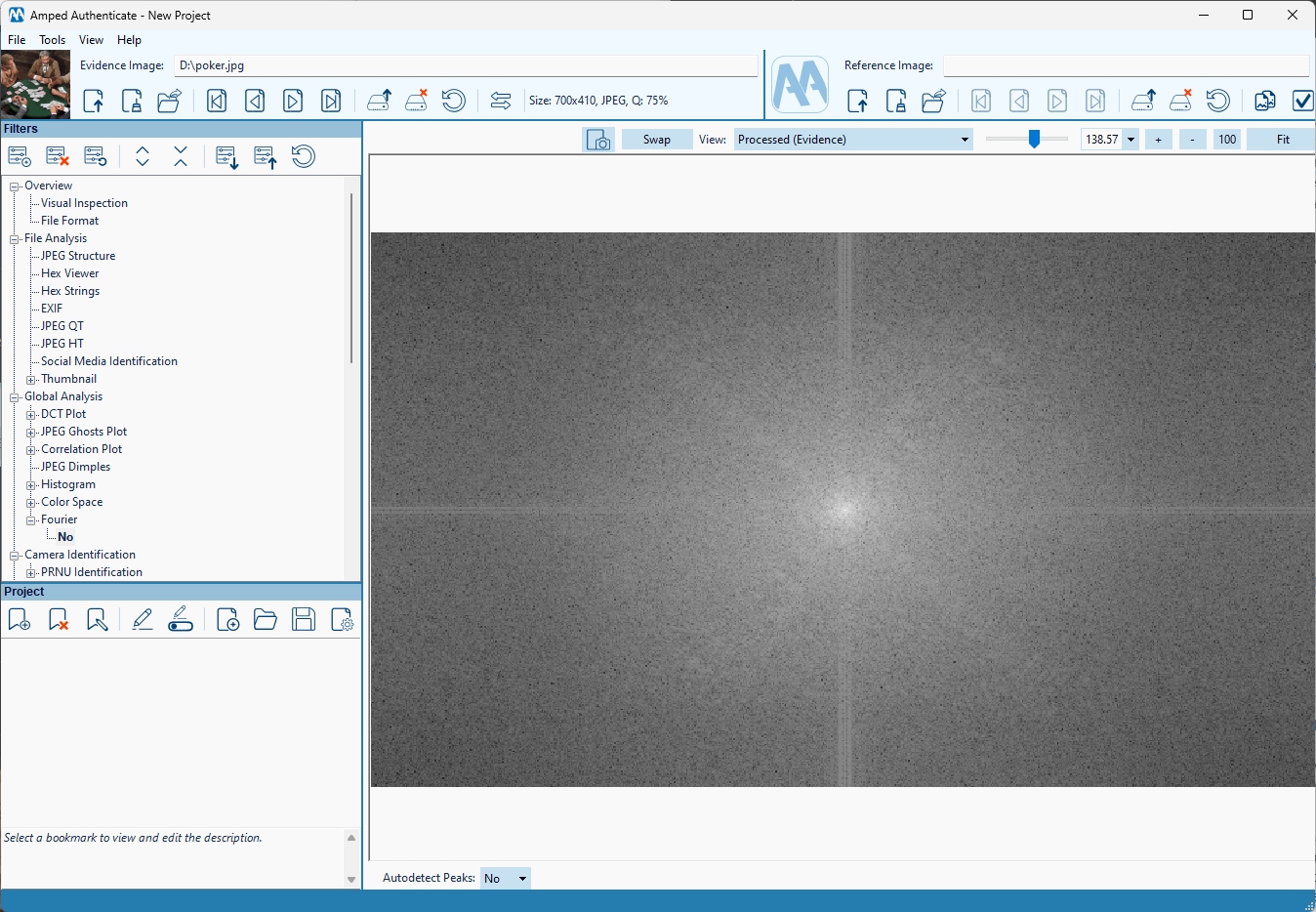
Let’s see an example, starting from the saloon image above. Interestingly, as documented in the scientific literature, this AI-generated image shows peculiar traces in the Fourier spectrum, as clearly visible in Authenticate’s Fourier filter.

This is rather suspicious if we consider that “natural” images have a Fourier spectrum which is more like this:
However, let us now downscale and compress the saloon image and make it like this:

Checking this image version in the Fourier filter shows fewer traces since the processing steps have “laundered” them.
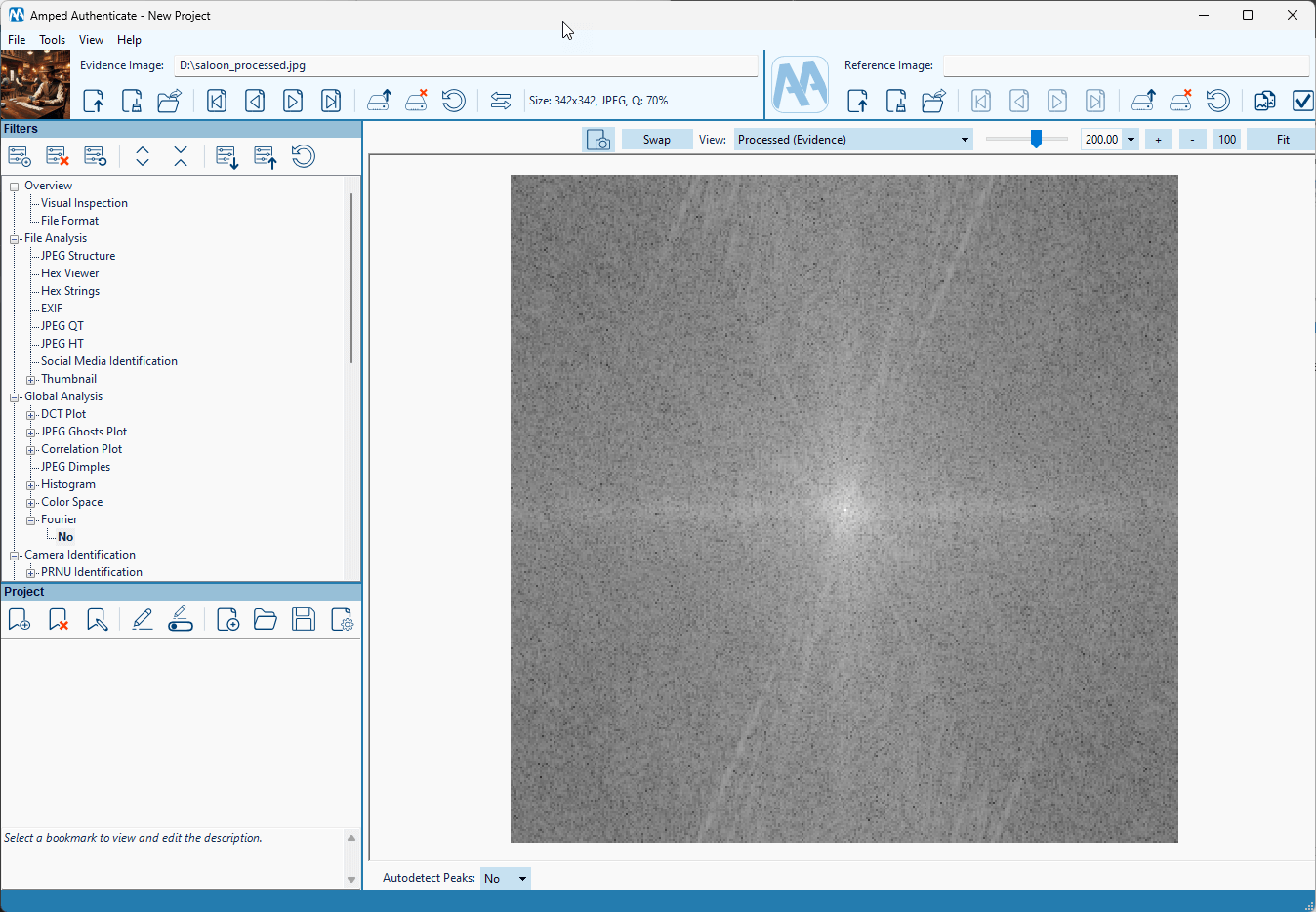
Instead, the Diffusion Model Deepfake filter is still confident about the answer.

Again, that doesn’t mean the filter will never be wrong. It simply means that in this example, and more generally in our experimental validation, it showed very good robustness to post-processing.
A Comment on the Use of AI
Here at Amped Software, user awareness is a top priority. Whenever possible, we favor model-based, fully explainable methods, as witnessed by the number of filters belonging to this category in Amped Authenticate. However, today’s research tells us that AI-based detectors deliver the best performance for detecting deepfakes, which is why we decided to include them in Authenticate. Indeed, Amped’s position is that AI can be used for image and video analysis, provided some safeguards are in place. Meanwhile, using AI to enhance images is currently too dangerous (interestingly, an AI-enhanced video was recently ruled inadmissible in US Court).
If the Diffusion Model Deepfake filter flags an image as deepfake, we recommend you deepen your analysis instead of blindly trusting the filter’s result. For example, within Amped Authenticate, you can check the Fourier spectrum, check whether shadows and reflections are consistent, and look for possible visual clues. A joint interpretation of several analyses is always the best way to increase your degree of support towards or against a hypothesis.
Conclusion
With the Diffusion Model Deepfake filter, we’re significantly extending Authenticate’s ability to identify deepfakes. We acknowledge that this is just the beginning: new diffusion models will emerge in the future, and the existing ones will improve even further. For this reason, we’re committed to monitoring the state-of-the-art and keeping our training datasets up to date to improve the filter with every release.
We recommend that you subscribe to our blog and follow us on social media so you’ll be updated on any developments brought to you by the enthusiastic Amped team!



