

In a nutshell: a digital image is created by a sequence of physical and digital processes. Ultimately, they produce a representation of light information in a specific moment in a specific place, as a sequence of 0s and 1s. The technical limitations of the imaging system will introduce some defects that will make the image different compared to the original scene, and often less intelligible during investigations. The image generation model aims to understand how these defects are introduced, in which order to correct them in the proper sequence and obtain a more accurate and faithful valid representation of the scene.
Why do we need the image generation model?
We’ve been teaching the image generation model in our Amped FIVE training classes for years. As an engineer, it looked so obvious to me that I took it for granted.
And yet, how many enlightened faces I have seen over the years! When you get it, it’s one of those moments of revelation, when all pieces of the puzzles stick together.
Understanding the image generation model draws the line between who tries to play with the image to try to get something out of it and who actually does forensic video enhancement with the aim of reconstructing a more faithful representation of the captured scene.
One of the most common questions we get asked is: “How can I justify to the court the fact that I processed an image used as evidence?”. The image generation model allows us to give a very simple reply: by understanding how defects are created and correcting them, we can obtain a more accurate representation of the scene (or subjects, or objects) of interest, compared to the original image or video. For those coming from traditional forensics, it’s like putting reagents to get fingerprints, but in a repeatable and non-destructive way.
What is the image generation model?
The image generation model represents a conceptual understanding of how the light coming from a scene in the physical world is converted into an image, and in the case of a digital image (or video) ultimately a sequence of 0s and 1s.
The image below summarizes the various phases of the image generation model: scene, camera, storage, view, and their respective subphases.
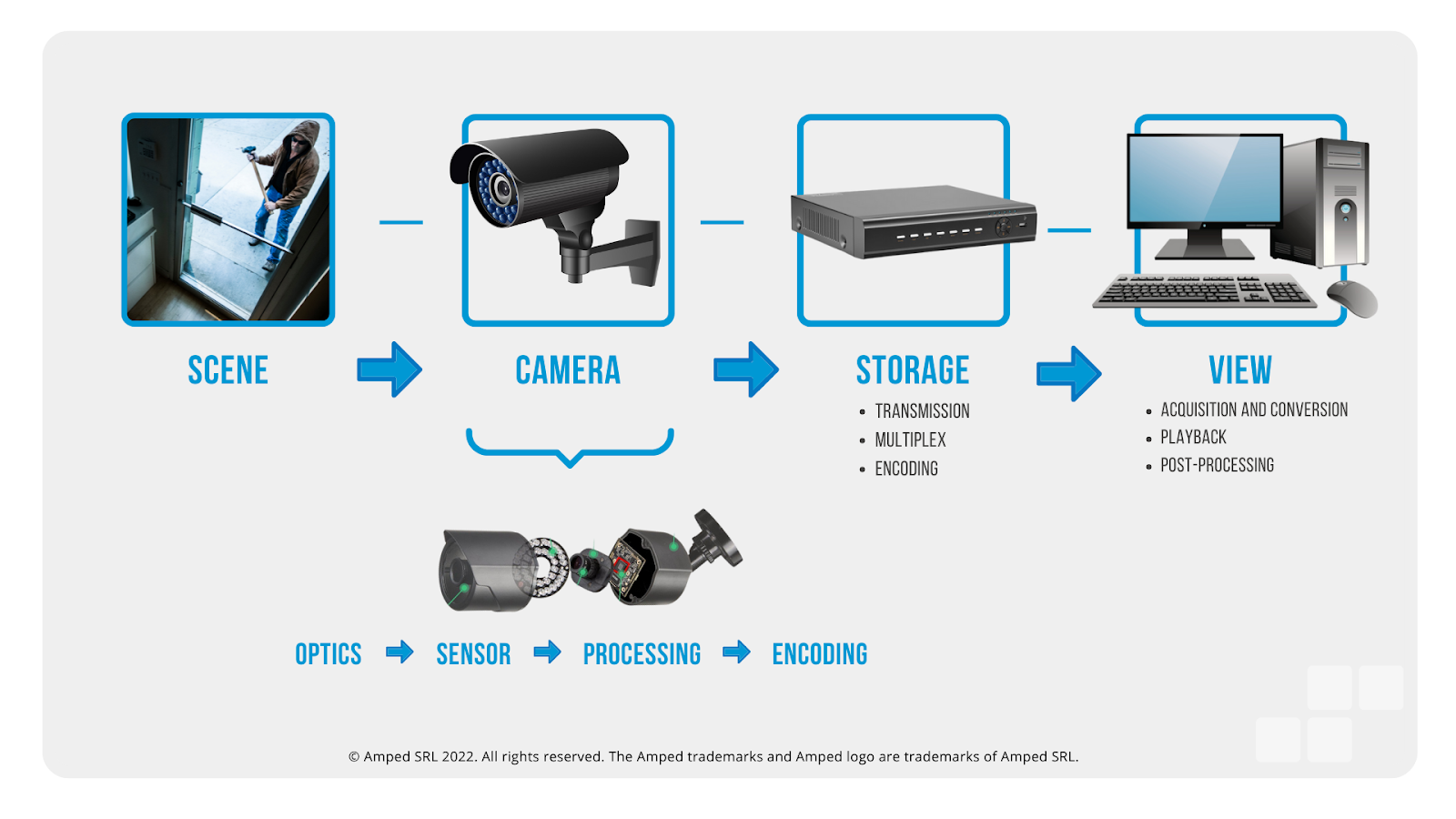
In each step of the process, there are technical limitations that introduce some differences between what would be an ideal image of the real world and the actual one that we get out of the imaging process.
A very straightforward example is the lens distortion introduced by wide-angle lenses. Straight walls appear curved in the image because of the features of the camera optics. Since the actual walls are straight and not curved, the distortion correction allows producing an image that is a more accurate representation of the real scene.

Defects
Many different defects are introduced in the various parts of the image generation model. Understanding the actual model for a specific case and which defect is introduced at each stage is key to scientifically enhancing the image.
We decided to use the word defect as a general term to describe any kind of problem, issue, or disturbance of the image. There’s no specific technical term generally used for this variety of topics, due to technical limitations of the imaging process. That is why we opted for this word.
In the following, we will refer to a generic case where a scene is taken by a Close-Circuit TeleVision (CCTV) system, encoded in a Digital Video Recorder (DVR), and later displayed. The actual situation may vary from case to case, and it’s important to be understood by the analyst. The image generation model for an image acquired by a digital camera or smartphone will differ. However, the same general concepts hold.
Phases
What are the various phases of the image generation model?
At a macro level, these are the phases of the image generation model
- Scene: this is the actual scene or event happening in the physical world, whose reflected light is going to be represented in the image.
- Camera: the light coming from the scene passes through the camera optics, then hits the sensor, which converts the light into a digital signal; this is then processed in various ways inside the camera and encoded into a usable format.
- Storage: the signal coming from the camera is transmitted, potentially multiplexed with signals from other cameras, and encoded in some way by the DVR, which usually includes strong compression.
- View: while the image has been technically generated at the previous phase, actually further processing is often needed the be visualized by the operator; depending on the system, acquisition, conversion, and playback are typical steps that need to be taken into account.
What defects are introduced at each phase?
Ideally, we would like to place each possible defect or technical limitation of an image in a specific phase. This, again, depends on the image generation model of the specific case, but we can define a quite general approach.
Please note that the descriptions of the defects below are not necessarily, technically and formally precise. It’s just to give a simple idea of the various defects and how they happen.
Scene
There are not many defects due entirely to the scene. One possible way to determine them is to think about “defects” that would be present not only on an image but also on the actual scene as perceived by a human observer in the place of the camera. One example would be atmospheric turbulence. Typical defects strictly related to the scene are:
- pattern noise, like a background pattern over a detail of interest (for example a fingerprint on a banknote, or a mosquito net) or from a recaptured image (such as a photo of a screen);
- strong perspective, such in the case of a camera positioned at an angle with respect to a license plate;
- long-distance from the detail of interest, causing it to appear too small in the image;
- atmospheric turbulence that can be seen looking far away on hot and humid days;
- poor lighting conditions, e.g. due to scarcity of light, or the presence of strong of a strong light source in an otherwise dark environment (this is explained more in detail in the next section).
Camera
Most of the defects in digital images come from this phase. However, they are not really due to the camera only, but to the combination of the camera’s features and those of the captured scene. For example:
- Is an image blurred because a car was running too fast (scene) or because the shutter speed was too low (camera)?
- Is an image too dark because there was too little light in the scene (scene) or because the exposure time of the camera was too little (camera)?
As you can see, most of the time it’s a relative combination of the two.
The camera phase can be actually divided into four subphases, each with its defects: optics, sensor, processing, and encoding.
Optics defects
Typical defects due to the optics are
- optical distortion which is clearly visible when straight lines appear as curved in the image;
- chromatic aberration: it is caused by colors of different wavelengths converging in slightly different parts of the image, and causes color artifacts on the external parts of the image;
- optical blur in images that are out of focus;
- motion blur, when the movement in the scene is too big compared to the aperture time of the shutter and basically transforms each point of the image into a line;
- loss of detail, usually caused by the antialiasing filter in the camera.
Sensor defects
Typical defects due to the sensor are related to the conversion of an analog signal into a digital one and are related to:
- brightness: when an image is too dark or too bright;
- contrast: when there is too little difference between dark and bright areas of the image;
- color issues: when the colors in the image don’t reflect well the actual ones;
- noise: random variation of pixel values;
- saturation and level compression: when details are lost either because they all have the maximum value, the minimum value or different slightly different intensities are given the same values;
- low resolution: this is due to the fact that the sensor has a limited resolution, and cannot capture all the small details of the real world;
- interlacing: this would deserve a complete explanation; in short, in an analog camera two consecutive frames are saved in the same image, alternating odd and even lines, thus losing half of the vertical resolution;
- low frame rate: the sensor values are read a limited amount of times per second, hence potentially missing very quick events;
- rolling shutter: some sensors are not read in their entirety at the same time, implying that different parts of the image relate to slightly different times, causing artifacts in fast-changing scenes.
Processing defects
Modern cameras typically do a lot of processing to the images before encoding them. They can be configured either manually or automatically. Typical defects from the processing subphase are:
- color artifacts from demosaicking: the sensor typically captures only a specific color per pixel, other color values should be interpolated from the neighboring ones, and this can cause artifacts;
- level compression, loss of detail, noise: image optimization is always a compromise; usually, if we make a dark image brighter (or vice versa) we lose some information on the other side or introduce level compression. Similarly, many devices do some form of denoising, which can cause a bit of blur (implying loss of details), or sharpening, which can cause noise amplification;
- advanced processing: modern cameras, especially smartphones, exploit very advanced kinds of processing for improving image quality, which can be based on artificial intelligence (AI) or other techniques to create portrait mode, panoramas, night mode, or simply to show a more appealing picture; this can create all kinds of artifacts and alterations to the picture, and users usually have little control over them.
Encoding defects
The last subphase is encoding, where the data is actually saved in a specific format. These are the typical defects:
- loss of detail, caused by the fact that image and video compression usually save memory by removing small details or copying them from similar parts in the same image or nearby frames;
- compression artifacts: compression may also cause the addition of new fictitious details as a side effect;
- interlacing: interlacing can sometimes happen at this phase, causing the same issues mentioned in the sensor subphase;
- wrong aspect ratio: this is a highly complex issue, already discussed in several posts (e.g., this one and this one): different formats and types of signals cause the ratio between the width and height of the image, to be different from how it should be in the real world, leading to squeezed or stretched objects.
Storage
This phase can be very simple and basically included in the Camera phase (in the case of digital cameras and smartphones). It could be more complicated in the case of DVRs and Network Video Recorders (NVRs). There may also be multiple encoding phases, each with similar issues.
We can divide this phase into 3 subphases: transmission, multiplexing, and encoding.
Transmission
The transmission phase is where communications happen between the camera and the storage. It can be wildly different. The storage can be local, in the cloud, or the signal could pass through an analog or digital connection. Depending on this, the defects can be very different:
- with a digital signal, such as in the case of IP cameras, the main issues are transmission errors and packet loss that can cause missing entire frames, glitches in parts of the image, or create artifacts;
- with an analog signal, such as in the case of analog cameras connected to a DVR, typical issues are random or pattern noise, caused by poor cabling or interferences.
Multiplexing
The next subphase is multiplexing. Signals from different cameras (and even different kinds of signals such as audio, timestamps, and other metadata) are put together in the same file or byte stream. There are different kinds of multiplexing:
- spatial multiplexing is when different cameras are put together in the same image, for example dividing each frame in quarters, thus reducing the resolution of every single source;
- temporal multiplexing is used when different frames of a video show different cameras: this may imply (especially in old VHS systems) that frames are discarded to alternate the signal from different cameras;
- digital multiplexing is when done at the digital file level: this, in turn, may be done at frame level (similar to temporal multiplexing), stream level (multiple standard streams inside the file), or byte level (typically used in proprietary video formats): it causes difficulties in playing back the video or the camera of interest, especially in the case of proprietary formats, where wrong decoding may cause artifacts, glitches and missing frames.
Encoding
Finally, there may be an encoding subphase with similar issues to the encoding in the camera phase. A particular case would be saving on a VHS in very old systems. They had their peculiar issues like scratches and misalignment. While it’s still possible to work on VHS, usually while reopening old (and cold) cases, it’s pretty rare nowadays.
View
Did you think it was all? The image generation process would technically finish once the final encoding is done. However, a saved video file is useless without displaying it. The process needed for doing so may introduce additional issues.
First of all, I need to get the video and make it playable. The first subphase is then acquisition and conversion. There are many different ways of acquiring and converting video evidence, some of which can deeply impact image quality. These are the most common ways to acquire a video from a DVR:
- export functions of the DVR: for example on a thumb drive, a CD/DVD, via a network connection, or cloud;
- forensic analysis of the DVR hard drive (byte level analysis), either manually or with specialized software tools;
- screen capture;
- analog capture of the video signal with a frame grabber.
This would be the subject of future posts. The last two should be used only as a last resort when other methods fail. I didn’t even want to put on the list the possibility of filming the DVR monitor with a mobile phone. Yet, that’s sadly pretty common (justifiable only in case of extreme urgency).
Issues
Different acquisition methods may need an additional conversion phase from a proprietary format and can introduce issues such as:
- wrong or excessive processing done by the player;
- wrong aspect ratio or resolution;
- compression artifacts and loss of details;
- duplicate or lost frames;
- loss of file integrity and original metadata.
Let’s not even talk about getting a video from cloud-connected cameras and social networks. There, the concept of “originality” is even more complicated.
And for mobile phones, it’s not always so straightforward. For example, when copying an image from an iPhone to a computer, depending on the settings and the application used, it may be converted behind the scenes from the HEIC to the JPEG format.
Playback
Then there’s the playback subphase. The most crucial aspect here is the quality and setting of the equipment used to view the video. A bad quality monitor, bad lighting conditions, or, even worse, using a projector may dramatically affect the displayed quality of the image and make it nearly useless.
In the case of old VHS tapes, every time you were playing a video you were reducing a bit the quality of the recording. A typical result was that the quality of the footage was somewhat ok, until the moment of interest that was watched several times by first responders, badly affecting the quality with scratches and jitters on the tape.
Post-processing
Finally, sometimes we also have to fight a very hard battle with wrong post-processing.
Sometimes it happens that we receive an image or video that’s already been subject to some tentative form of naive enhancement or processing. Often the original has been lost, and this is all we have. In this case, we need to understand what has been done in order to (hopefully) recover some damage.
Often there’s not much to do, such as in the case of an interlaced frame that has been resized or a heavily recompressed video. Understanding what has been done it’s important nevertheless.
The cheat sheet
In the above section, I’ve explained the image generation model and how different defects are added in each phase. We explain this topic much more in-depth during our Amped FIVE classes. We go into detail on each step and show examples of every defect.
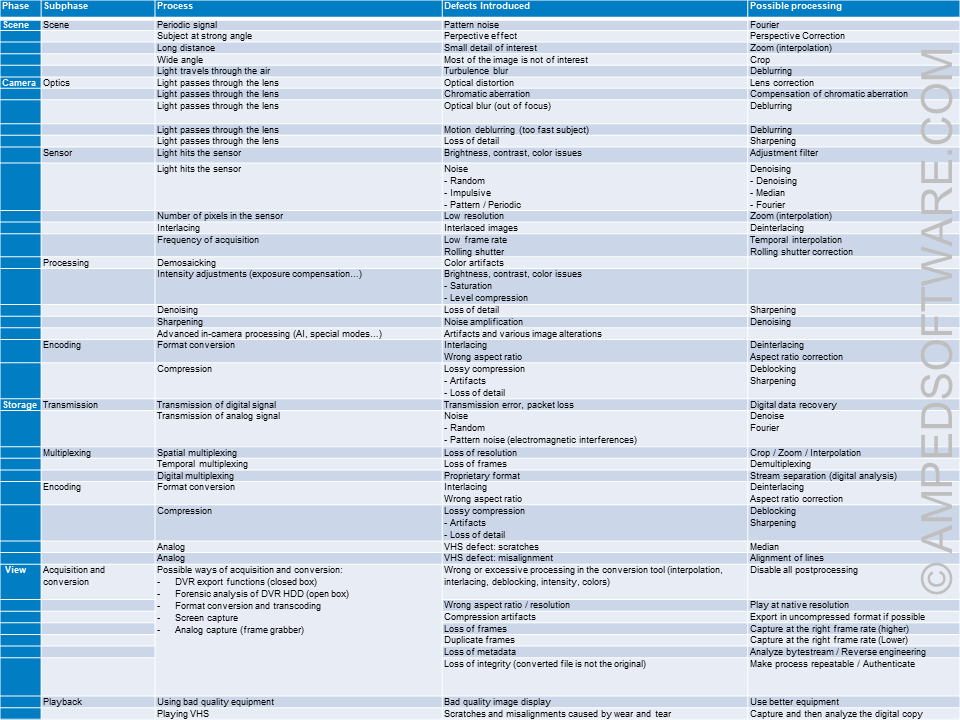
I think this topic is so important, and overlooked. I decided to make available for the readers of this blog a table summarizing all the defects and possible solutions. It is in the right order according to the image generation model.
How to use it
The table has the following columns:
- The Phase of the image generation model (Scene, Camera, Storage, View)
- The relative Subphase: for example, the phase Camera is divided into the subphases Optics, Sensor, Processing, and Encoding
- The Process which happens at every step: could be physical (e.g. light passes through the optics) or digital (e.g. lossy compression)
- The Defect Caused by each process, because of some technical limitation
- A Possible Processing to reduce or attenuate the defect.
While this cheat sheet can be very useful for Amped FIVE users, it’s not software-specific. Most of the possible processing can be found in some Amped FIVE filters. However, they don’t necessarily use the same exact nomenclature since they are more generic. For example “Lens Correction” can be done with either the filter Undistort or Correct Fisheye in FIVE and maybe by some other filters in the future.
Please note that the cheat sheet covers the most generic situation possible. Your case may and often will be different. Also, for conciseness and usability, some simplifications have been done, and some details may not always be formally correct.
The main takeaway from it should be “understanding” better how the image has been generated and how defects have been introduced at each phase to correct them in the best possible way.
How to apply the image generation model in practice?
Some time ago, I used to ask the analysts: “in which sequence do you correct image defects?”. Either they didn’t have a specific workflow, or they replied “correct the worst problem first.” In my opinion, while this is something that can be done during the triage phase, it’s not actually the right way to forensically process an image.
Maybe if an image is too dark, I need to make it brighter before actually correcting optical distortion or blur. In theory, if we just used what are called “linear filters,” the order wouldn’t matter much. But real life is much more complex.
The image generation model gives me a conceptual framework for defining scientifically:
- Which filters I should apply to correct the defects
- The order in which to apply them
Correction order
As discussed in this article, it’s as simple as inverting the order.
The footage you’re working with is the product of a long acquisition and processing chain, which usually introduced several artifacts. The most reasonable way to go is to compensate for these artifacts in reverse order. This sounds pretty intuitive even in everyday life. When you’re dressing you normally wear clothes in a certain order. When you undress (so you’re undoing the chain) you take them off in the reverse order.

And if you get the order wrong, it may make a huge difference in the results.
So, reading the above cheat sheet table:
- The image is created following the steps from the top to the bottom, and at each step, some defects are introduced
- In order to process the image, I should follow the steps in reverse, applying the “Possible Processing” (when needed) from the bottom to the top.
As usual, there may be exceptions. It may not always be 100% clear when one defect was created. At least considering these aspects gives us a direction to follow.

What’s the science behind the image generation model?
While the intuitive explanation of the reversal makes perfect sense, as forensics scientists we need something more. Luckily, there’s also a mathematical justification for this approach. However, the mathematical justification works when you have the exact inverse of all functions (in our case, defects). This is of course false in the image restoration case. We only have approximate inverse operators, since mathematical models are approximate representations of reality. That means, if you have a blurred image, you can effectively deblur it with Amped FIVE. However, it will never be as perfect as if no blur existed at all.
Therefore, we are trying to extend the mathematical justification to a more realistic scenario in image processing. It is a very complex topic. We’ve partnered with professors from both mathematics and engineering faculties to put the pieces together. We’ve worked already for a few years in this direction, and we hope to be able to publish something soon!
Conclusions
This is definitely one of the longest blog posts I’ve written. Still, I think it’s a fundamental topic that we have explained since the very beginning in our training courses. It deserves to be thoroughly explained, and be made more widely understood in our industry.
If you are reading this, and you’d like to discuss this further, feel free to contact me. You can easily reach me on LinkedIn, our Discord community, or with good ol’email!
by Martino Jerian, CEO and Founder of Amped Software



